Slapo: A schedule language for progressive optimization of large deep learning model training
简介
Slapo 的这篇工作主要提供了一种“调度”语言,通过解耦模型定义和执行,来简化模型的优化(具体来说只是提供了更加细粒度的原语,直接看下文,文章和实现都特别简单)。在 PyTorch 基础之上构建,大约有3K行代码(工作感觉很鸡肋)。
文章主要观点是:现在的模型优化方法特别多,要用他们缺乏一定泛型能力(结合各种优化能力很难,比如要用 TP 可能得用 Megatron-LM 框架去跑代码,ZERO优化又要 deepspeed 这些框架),代码不好写不好DEBUG。这些优化又有各种调优参数,Slapo目前只说了提供了这样一种接口(这篇工作只实现了 checkpoint ratio 和 batch size 这两个参数的调优)。
Slapo 的调度语言分为两部分(主要根据是否修改计算流程,或者说文中说的 forward 函数来区分):1. 模型和参数的调度 2. 计算的调度。
第二部分主要涉及计算,可以做算子融合、替换为高效的 kernel(这些能力依赖底层调用的 DL 编译器,需要去捕获一张静态计算图作为输入)。而第一部分只是模型参数的处理,就不需要捕获计算图。
Schedule Modules and Parameters
所谓的模型和参数的调度,直接看下图。提供了4种原语(其实就是4个函数 replace 做模块替换,shard 用于做 TP,sync 用于同步,checkpoint 用于插入 checkpoint,而且 pytorch 自己也有,例如 shard 和 sync 用 DTensor 就能实现,checkpoint 自带就有,replace 直接重新赋值就行了,所以感觉很鸡肋)。
图(b) 中的 replace 函数,可以将模块进行等价替换,比如图中的 attention 模块可以用等价的 eff_attn 模块替换,这里就是把 QKV 这几个矩阵 concatenate。图(c) 中的 shared 和 sync 就是用来做 TP 的,把模型切片,然后手动插入 sync 来表示在什么时候同步。
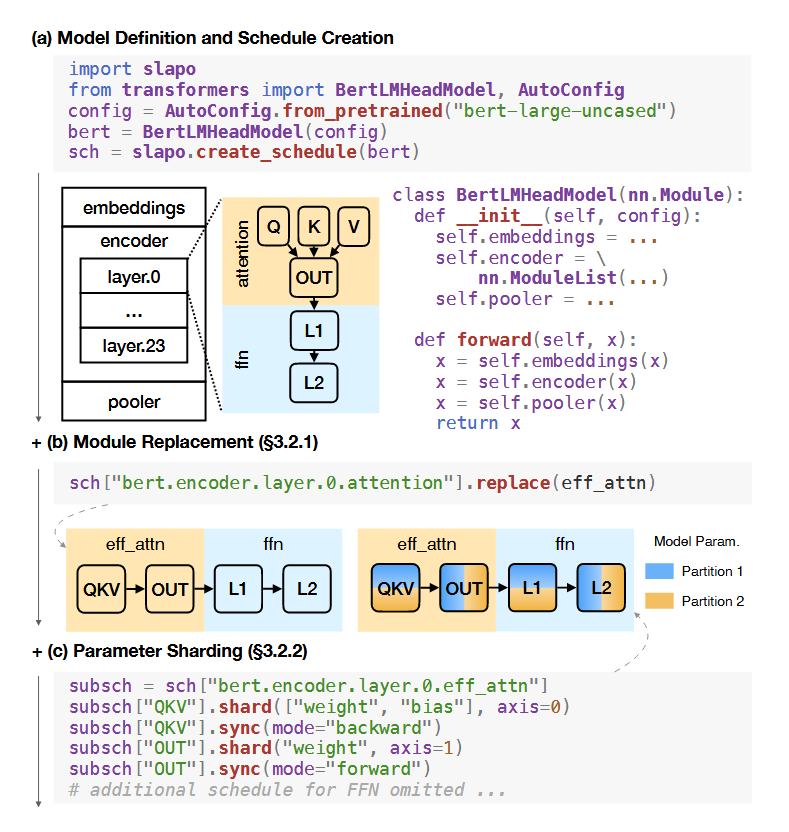
Schedule Computations
首先提供一个叫 trace 的原语,来构建一颗树(这里和 pytorch 一样),叶子节点就是不可再分的模块比如 Linear。提供了一个 find 的原语,直接在构建的树里面去找是否有定义好的模式(应该就是一个简单的子树查询)。然后是提供的 fuse 原语,调用底层的 DL 编译器去做算子融合。然后也提供了类似的 replace,DL 编译器不给力时可以直接用用户定义的 kernel 来替换。也提供 checkpoint。
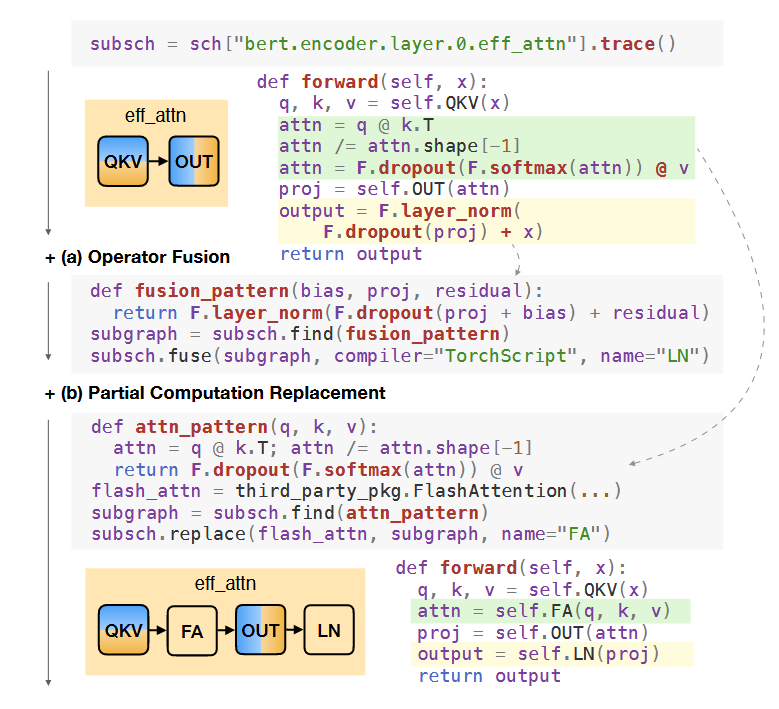
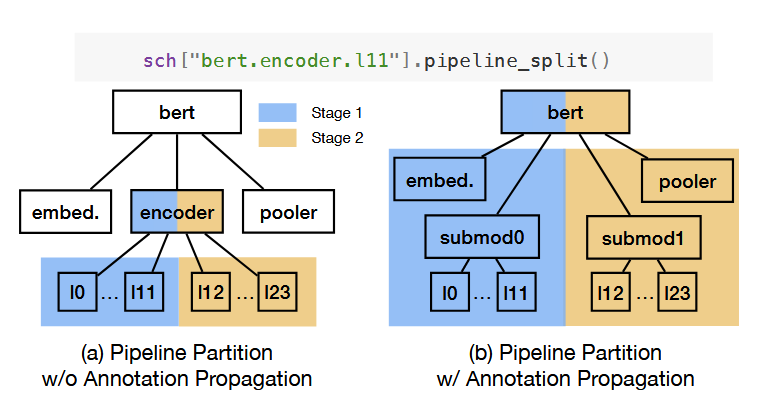
最后提供了一个 pipeline 并行的处理,如下图,主要是来解决全部分区的问题,用户插入了 pipeline_split 后如图a,白色部分还是得纳入 stage,用一个简单的祖先搜索就搞定了。
总结
实验上去和 Megatron-LM 和 DeepSpeed 比性能,感觉没有什么可比性,Slapo 是手动去构建的策略,相当于可以人为调整出一个最优的方法。
从下图给出的 example 看起来,感觉并不能达到所说的能够简化多少开发:他用的 sync 和 shard 我用 torch 一样可以替代,如下下图。find 和 hook 的方式同样也能找到 hook 的方式去做。

